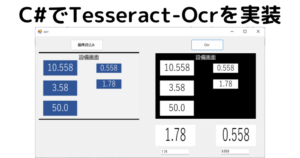
今回はTesseract-Ocrを使って画像から文字を読取り出力する方法をご紹介します!
今回の内容は工場勤務の方から相談があった内容となります。
工場勤務の方や事務系の方にも参考になる内容ではないかと思います。
「ココナラ」でC#、OpenCvSharpを使った画像処理アプリの作成を行っています。
もし、作成依頼やお困りごとがあればお気軽にご相談ください!

相談内容

設備の操作盤(画面)に表示される出力結果の数値をExcelに手入力しているが、入力ミスや入力忘れが多いため、自動化がしたい。
現状では、設備画面をカメラで撮影(遠隔操作)してそのデータを見て手入力している状態。
「写真データから数値を抽出」してExcelに自動転記できないかとの相談がありました。
ということで、実際に依頼があった内容を作成してみました!
※今回は実際の写真は使用できないため、絵のデータで検証しています。
また、Ocrができるかというところまでで、Excel出力の部分は実装していません。
動作環境
- Windows10
- VisualStudio2019
- OpenCvSharp4
- Tesseract4
前準備
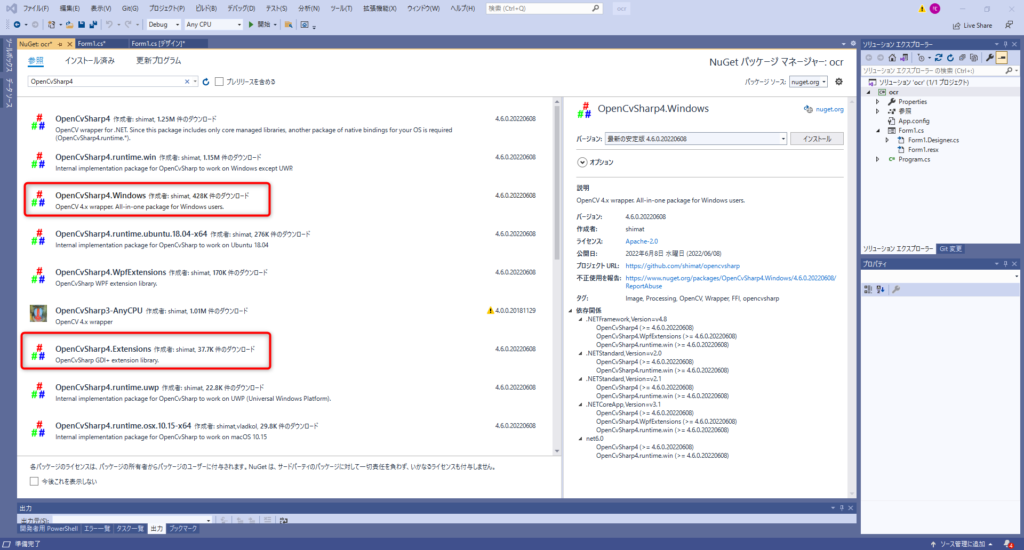
①OpenCvSharp4のインストール
「OpenCvSharp4.Windows」と「OpenCvSharp4.Extensions」をインストールします。
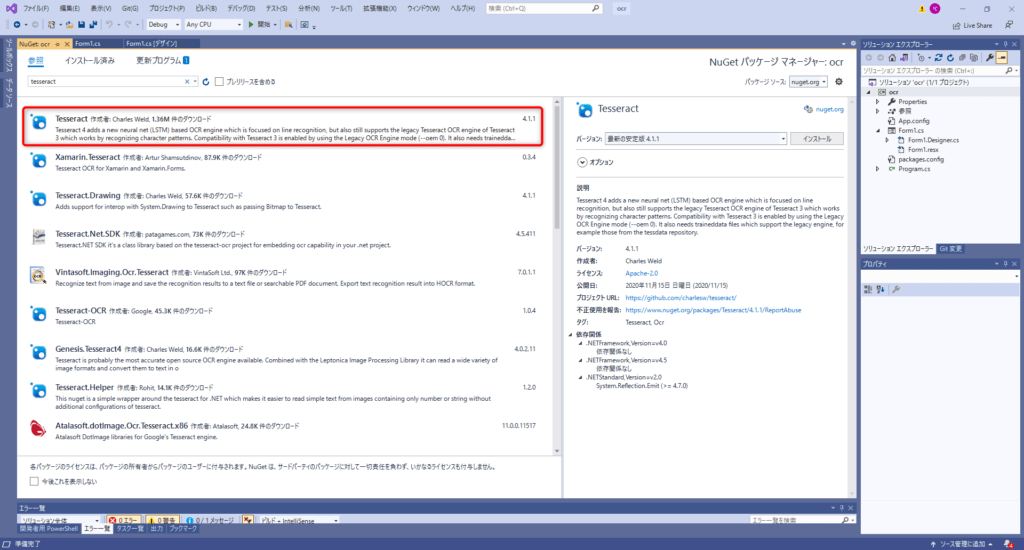
②Tesseract4のインストール
1番上にある「Tesseract」をインストールします。
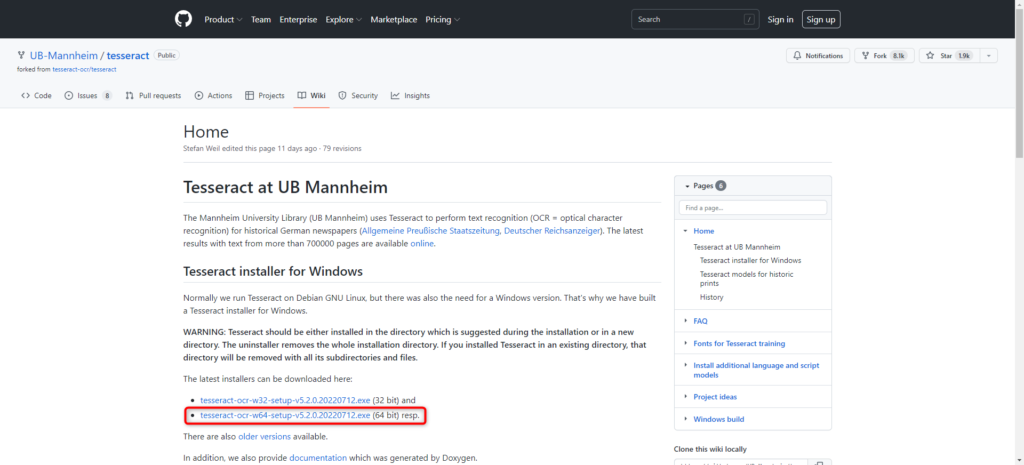
③Tesseractを使用するための学習データのダウンロード(githubから)
Tesseractを使用する際には文字の認識をさせるために、学習済みのデータをダウンロードする必要があります。
NugetからTesseract4をインストールするだけでは使用できないので気を付けましょう!
下記にアクセスしてwindows用のインストーラーをダウンロードします。今回は64bitの方をダウンロードしました。
https://github.com/UB-Mannheim/tesseract/wiki
次にインストーラを起動します。
起動するとセットアップ画面が表示されるので「Next」をクリック
次にライセンスについての同意画面が出てくるので「I Agree」をクリック
次に使用できるユーザーの選択画面になります。今回はデフォルトを選択します。
オプションの選択をします。今回は数値とドットの検出のみのため、オプションの選択は不要です。
日本語を検出させたい場合は下記の項目を選択する必要があります
・Additional script data
「Japanese script」と「Japanese vertical script」を選択
・Additional langage data
「Japanese」と「Japanese (vertical)」を選択
ダウンロード先を指定し、「Next」をクリック
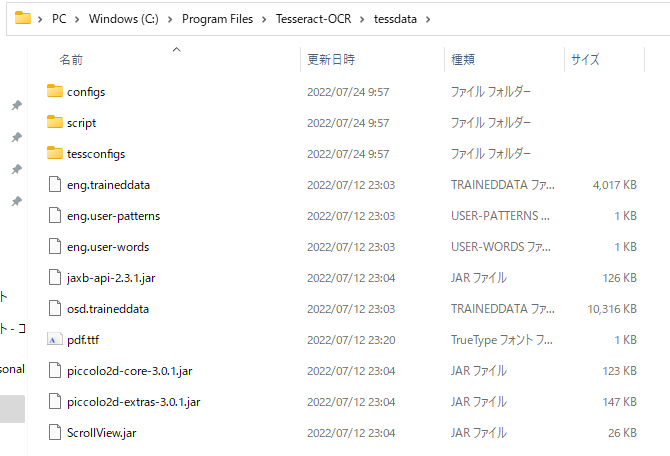
指定したダウンロード先の中身を見ると下記のようなデータが入っています。
「Tesseract-OCR」には多くのものが入っていますが、今回使用するのは「tessdata」フォルダのみになります。
プロジェクト内にコピーすることにより、配布した際に「Tesseract-OCR」をダウンロードしていない環境でも使用できるようになります。
「tessdata」フォルダをプロジェクトの「bin」⇒「Debug」の中にコピーしておきます。
ソースコード
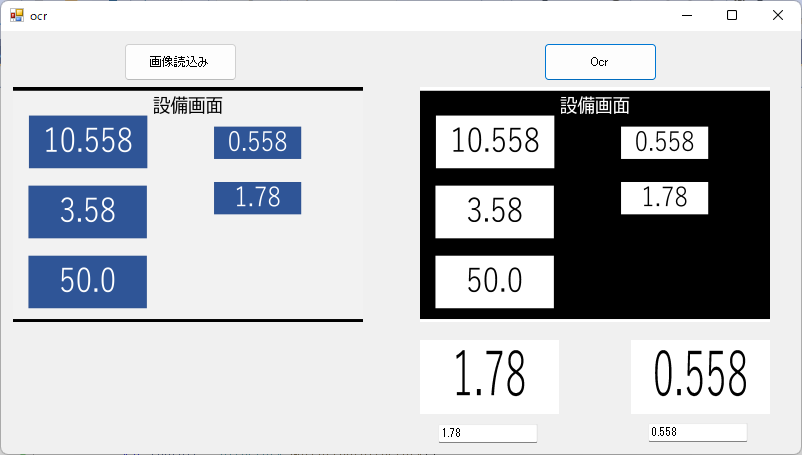
処理の大まかな流れは以下の通りです。
①画像読込み
②グレースケール・2値化
③輪郭抽出
④輪郭の面積を検出し、必要な箇所の画像を切り取る(今回は読取りたい場所の面積が決まっていたので面積で判定しました)
⑤切り取った画像をOcrで文字を認識させる
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.IO;
using OpenCvSharp;
using OpenCvSharp.Extensions;
using Tesseract;
namespace ocr
{
public partial class Form1 : Form
{
private Mat _srcMat;
private Mat _thresholdMat;
private List<Mat> _rectMats;
public Form1()
{
InitializeComponent();
//PictureBoxのサイズに合わせて表示
pictureBox1.SizeMode = PictureBoxSizeMode.StretchImage;
pictureBox2.SizeMode = PictureBoxSizeMode.StretchImage;
pictureBox3.SizeMode = PictureBoxSizeMode.StretchImage;
pictureBox4.SizeMode = PictureBoxSizeMode.StretchImage;
}
private void button1_Click(object sender, EventArgs e)
{
//画像読み込み
_srcMat = Cv2.ImRead(@"C:\Users\uchiy\Desktop\設備画面画像.png");
pictureBox1.Image = BitmapConverter.ToBitmap(_srcMat);
//グレースケール
var grayMat = _srcMat.CvtColor(ColorConversionCodes.BGR2GRAY);
//2値化
_thresholdMat = grayMat.Threshold(230, 255, ThresholdTypes.BinaryInv);
pictureBox2.Image = BitmapConverter.ToBitmap(_thresholdMat);
}
private void button2_Click(object sender, EventArgs e)
{
//ジャグ配列
OpenCvSharp.Point[][] contours;
OpenCvSharp.HierarchyIndex[] hierarchyIndexes;
_rectMats = new List<Mat>();
//輪郭抽出
_thresholdMat.FindContours(out contours, out hierarchyIndexes, RetrievalModes.External, ContourApproximationModes.ApproxNone);
foreach (var contour in contours)
{
var area = Cv2.ContourArea(contour);
if(area <= 100000)
{
continue;
}
else
{
if(area <= 200000)
{
//指定した面積の外接矩形の情報(座標値や幅、高さ)を得る
var retval = Cv2.BoundingRect(contour);
var rect = new OpenCvSharp.Rect(retval.TopLeft, new OpenCvSharp.Size(retval.Width, retval.Height));
//検出した外接矩形を切り出し、Listに追加する
_rectMats.Add(_thresholdMat.Clone(rect));
}
}
}
pictureBox3.Image = BitmapConverter.ToBitmap(_rectMats[0]);
pictureBox4.Image = BitmapConverter.ToBitmap(_rectMats[1]);
//tessdataのパスを指定
var rootDir = Directory.GetCurrentDirectory();
var langPath = rootDir + @"\tessdata";
//tesseractでの使用する言語を指定
var langStr = "eng";
var readTexts = new List<string>();
//検出した画像分繰り返す
foreach(var rectMat in _rectMats)
{
using (var tesseract = new TesseractEngine(langPath, langStr))
{
//使用する文字を指定する(今回は数字と.のみを検出)
tesseract.SetVariable("tessedit_char_whitelist", "1234567890.");
//画像をMatからBitMapに変換
var rectBitMap = BitmapConverter.ToBitmap(rectMat);
//画像データを渡してOcrを実行
Page page = tesseract.Process(rectBitMap);
readTexts.Add(page.GetText());
}
}
textBox1.Text = readTexts[0];
textBox2.Text = readTexts[1];
}
}
}①画像の読み込み~③輪郭抽出
①画像の読み込み~③輪郭抽出までは下記の記事で詳細を書いるので、ご覧下さい!
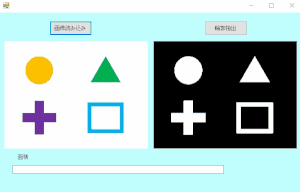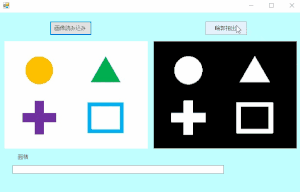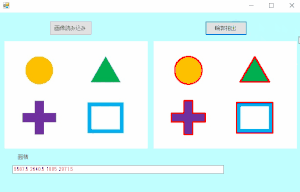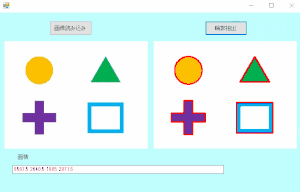
④輪郭の面積を検出し、必要な箇所の画像を切り取る
今回は検出をさせたい箇所の面積が他の部分と異なっているため、面積指定で検出をさせました。
検出させたい箇所の面積が170000だったため、100000以上、200000以下の面積のものを処理するというコードになっています。
Cv2.BoundingRectはFindContoursで検出した点群データから外接矩形の座標を計算することができます。
「TopLeft」、「Width」、「Height」などの情報が得られるので、そのデータをもとに、必要箇所の画像を切り抜きます。
※必要な箇所だけを切り取ることで、Ocrの読取り精度を向上させることができます(私の経験上の感覚)
private void button2_Click(object sender, EventArgs e)
{
//ジャグ配列
OpenCvSharp.Point[][] contours;
OpenCvSharp.HierarchyIndex[] hierarchyIndexes;
_rectMats = new List<Mat>();
//輪郭抽出
_thresholdMat.FindContours(out contours, out hierarchyIndexes, RetrievalModes.External, ContourApproximationModes.ApproxNone);
foreach (var contour in contours)
{
var area = Cv2.ContourArea(contour);
if(area <= 100000)
{
continue;
}
else
{
if(area <= 200000)
{
//指定した面積の外接矩形の情報(座標値や幅、高さ)を得る
var retval = Cv2.BoundingRect(contour);
var rect = new OpenCvSharp.Rect(retval.TopLeft, new OpenCvSharp.Size(retval.Width, retval.Height));
//検出した外接矩形を切り出し、Listに追加する
_rectMats.Add(_thresholdMat.Clone(rect));
}
}
}⑤切り取った画像をOcrで文字を認識させる
Tesseractを使用する際には学習させたデータ「tessdata」が必要となります。
GitHubからダウンロードした「tessdata」のパスを入力します。
今回は配布した場合のことを考えてbin⇒Debugの配下に入れてあります。
どの環境からでも動くようにDirectory.GetCurrentDirectory()にて現在の作業ディレクトリを取得し、そこにtessdataを付けくわえてパスを指定しています。
Tesseractをインスタンスする際に「tessdata」のパスと使用する言語を指定する必要があります。
今回は英語をダウンロードしたので「eng」と入力します。
SetVariableにて使用する文字の指定をすることができます。
今回は数値とドットのみの検出のため、検出精度向上のために英語を省いています。
//tessdataのパスを指定
var rootDir = Directory.GetCurrentDirectory();
var langPath = rootDir + @"\tessdata";
//tesseractでの使用する言語を指定
var langStr = "eng";
var readTexts = new List<string>();
//検出した画像分繰り返す
foreach(var rectMat in _rectMats)
{
using (var tesseract = new TesseractEngine(langPath, langStr))
{
//使用する文字を指定する(今回は数字と.のみを検出)
tesseract.SetVariable("tessedit_char_whitelist", "1234567890.");
//画像をMatからBitMapに変換
var rectBitMap = BitmapConverter.ToBitmap(rectMat);
//画像データを渡してOcrを実行
Page page = tesseract.Process(rectBitMap);
readTexts.Add(page.GetText());
}
}
textBox1.Text = readTexts[0];
textBox2.Text = readTexts[1];※出力結果より、検出した画像は上から順番に検出しているわけではなさそうです。
「1.78」がList[0]に入っているため。
まとめ
以上がTesseract-Ocrを使った文字抽出となります。
文字の抽出する部分は非常に短く簡単に実装することが可能です。
簡単なので、是非試してみてください!
C#で画像処理を学ぶためのおススメの書籍
C#でOpenCvを扱う方法などを詳しく解説してくれています。
C#で画像処理を解説してくれている本がほとんどない中、こちらの書籍はいろいろなメソッドの使い方等を事例を交えて解説してくれているため、非常に参考になります。
私はこちらの書籍を参考に画像処理を実装しました。
是非参考にしてみてください。
C#の基本が学習したいという方におススメのスクール:侍エンジニア塾のエキスパートコース